The AI Transformer architecture is one of the most influential breakthroughs in modern artificial intelligence. It powers today’s large language models, state-of-the-art translation systems, generative AI tools, and multimodal applications that combine text, images, audio, and video. Yet despite its success, the Transformer has a fundamental bottleneck that increasingly limits how far it can scale.
This article explains how the Transformer architecture works from the ground up, why it replaced older neural network designs, and what its core bottleneck is—both technically and practically. Written with EEAT principles in mind, this guide is designed for engineers, students, product leaders, and curious professionals who want a clear, trustworthy, and deeply informative explanation.
Why the Transformer Changed AI Forever
Before Transformers, most sequence-based AI systems relied on Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) models. These architectures processed data one step at a time, making them slow, hard to scale, and ineffective at capturing long-range dependencies.
Transformers solved these problems by introducing a radically different idea:
Process all elements of a sequence in parallel using attention, not recurrence.
This single shift unlocked massive performance gains and made it feasible to train models on entire libraries of text, millions of images, or hours of video.
The Core Idea Behind the Transformer
At its heart, the Transformer answers one question:
How does each element in a sequence relate to every other element?
Instead of reading text word by word, the Transformer looks at all words simultaneously and learns which ones matter most to each other.
This is accomplished using a mechanism called self-attention.
Read Also: Governments Push for AI Identity Verification Systems: Benefits, Risks, and What Citizens Must Know
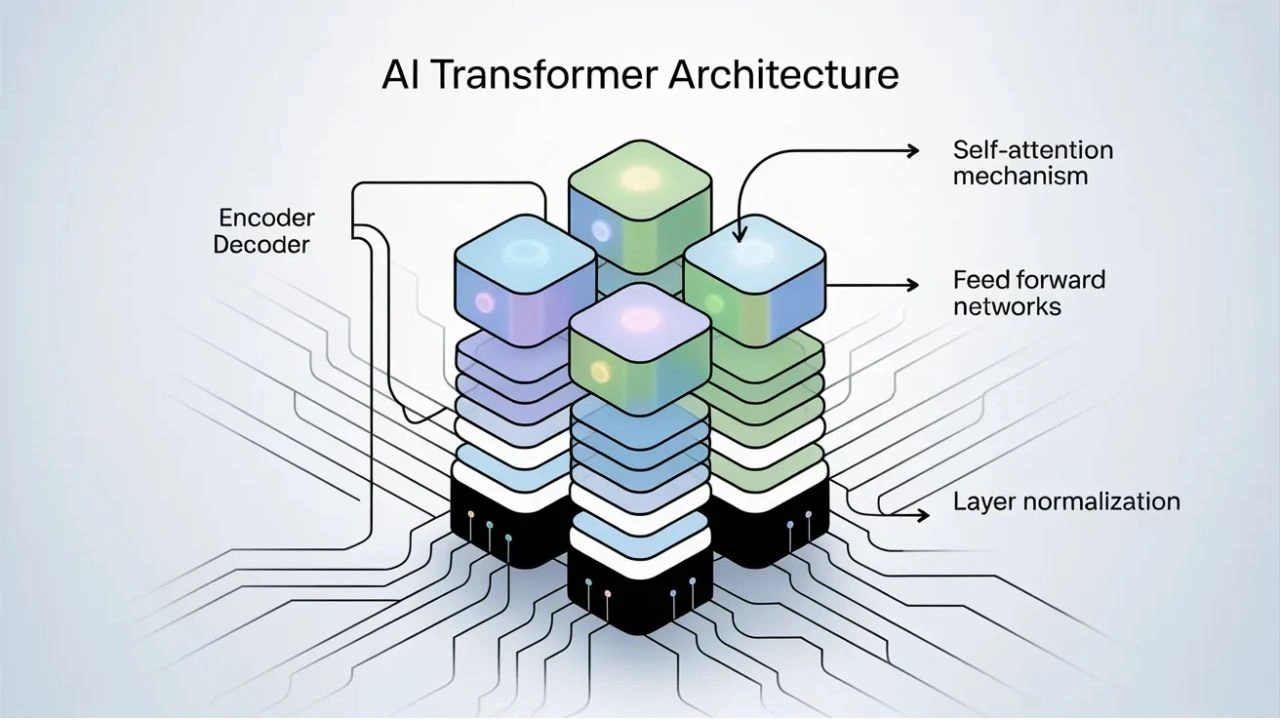
High-Level Structure of the Transformer
A standard Transformer consists of:
- Input embeddings
- Positional encoding
- Stacked Transformer layers
- Output projection
Each Transformer layer contains:
- Multi-head self-attention
- Feed-forward neural networks
- Residual connections
- Layer normalization
Let’s break these down clearly.
Step 1: Input Embeddings – Turning Tokens Into Vectors
Transformers do not understand raw text. Instead, text is first broken into tokens (words, subwords, or characters).
Each token is converted into a dense numerical vector called an embedding.
These embeddings:
- Capture semantic meaning
- Allow similar words to have similar representations
- Serve as the model’s internal “language”
However, embeddings alone are not enough.
Step 2: Positional Encoding – Teaching Order Without Sequence
Unlike RNNs, Transformers have no built-in sense of order.
To fix this, positional information is injected using positional encodings, which tell the model:
- Where a token appears in the sequence
- How far apart tokens are from each other
These encodings are added to the embeddings and allow the model to distinguish between:
- “Dog bites man”
- “Man bites dog”
Without positional encoding, meaning would collapse.
Step 3: Self-Attention – The Heart of the Transformer
Self-attention is what makes Transformers powerful.
For every token, the model asks:
- What other tokens should I pay attention to?
- How important is each one?
Query, Key, and Value
Each token embedding is projected into three vectors:
- Query (Q) – what this token is looking for
- Key (K) – what this token offers
- Value (V) – the information it carries
The attention score between two tokens is computed by comparing the query of one token with the key of another.
In simple terms:
Tokens attend more strongly to tokens that are more relevant to them.
Step 4: Attention Weighting and Context Building
The attention scores are:
- Scaled
- Passed through a softmax
- Used to weight the value vectors
This produces a context-aware representation for each token—one that reflects the entire sequence, not just local neighbors.
This is why Transformers handle long-range dependencies so well.
Step 5: Multi-Head Attention – Looking From Multiple Perspectives
Instead of one attention mechanism, Transformers use multiple attention heads.
Each head:
- Focuses on different relationships
- Captures different linguistic or semantic patterns
For example:
- One head may track subject-verb relationships
- Another may track coreference
- Another may track temporal dependencies
The outputs of all heads are concatenated and projected into a final representation.
This diversity of attention is a major reason Transformers outperform older models.
Step 6: Feed-Forward Networks – Non-Linear Processing
After attention, each token representation passes through a position-wise feed-forward neural network.
This:
- Applies non-linear transformations
- Expands representational capacity
- Allows complex feature interactions
Importantly, this network is applied independently to each token, making it efficient and parallelizable.
Step 7: Residual Connections and Layer Normalization
To stabilize training and enable deep architectures, Transformers use:
- Residual connections (skip connections)
- Layer normalization
These techniques:
- Prevent vanishing gradients
- Improve convergence
- Enable training of very deep models
Without them, modern Transformers would not scale.
Encoder-Only, Decoder-Only, and Encoder-Decoder Transformers
Transformers come in different architectural variants:
Encoder-Only
Used for:
- Classification
- Search
- Semantic understanding
Example use cases:
- Text embeddings
- Sentiment analysis
Decoder-Only
Used for:
- Text generation
- Code generation
- Chat systems
This is the architecture behind most large language models.
Encoder-Decoder
Used for:
- Translation
- Summarization
- Structured transformation tasks
Each variant shares the same attention-based core.
Why Transformers Scale So Well
Transformers succeeded because they:
- Are fully parallelizable
- Capture global context
- Scale efficiently with data and compute
- Improve predictably with size (scaling laws)
This allowed researchers to push from millions to hundreds of billions of parameters.
But this success exposed a serious limitation.
The Main Bottleneck of the Transformer Architecture
Despite all its strengths, the Transformer has a fundamental bottleneck:
Self-attention has quadratic time and memory complexity with respect to sequence length.
Let’s unpack why this matters.
Understanding the Quadratic Bottleneck
If a sequence has N tokens, self-attention requires computing relationships between every pair of tokens.
That means:
- Time complexity: O(N²)
- Memory complexity: O(N²)
As sequences get longer:
- Computation explodes
- Memory usage skyrockets
- Latency increases dramatically
This makes long-context processing extremely expensive.
Why This Bottleneck Is a Serious Problem
The quadratic scaling affects:
- Long documents
- Full codebases
- Video and audio streams
- Scientific data
- Agent memory systems
Even powerful GPUs struggle with very long sequences.
This is why many models:
- Limit context length
- Truncate inputs
- Use sliding windows
The bottleneck is not theoretical—it is a real deployment constraint.
Practical Consequences of the Bottleneck
High Infrastructure Costs
Longer context requires:
- More GPUs
- More memory
- More energy
This limits accessibility and increases operational costs.
Latency Issues
Real-time applications struggle when attention computations grow too large.
Model Design Trade-Offs
Developers must choose between:
- Model size
- Context length
- Speed
You can’t maximize all three simultaneously with standard Transformers.
Research Directions Addressing the Bottleneck
This limitation has sparked intense research into alternatives and optimizations.
Sparse Attention
Only attend to a subset of tokens instead of all tokens.
Benefits:
- Reduced computation
- Better scaling
Trade-off:
- Potential loss of global context
Linear Attention
Reformulates attention to scale linearly with sequence length.
Benefits:
- Massive memory savings
Challenges:
- Approximation errors
- Stability issues
Memory-Augmented Transformers
Store long-term information externally.
Examples:
- Retrieval-augmented generation
- External vector databases
Chunking and Hierarchical Models
Break long sequences into manageable segments.
This works well for:
- Documents
- Videos
- Structured data
Is the Bottleneck a Deal-Breaker?
No—but it defines the limits of current architecture.
The Transformer remains dominant because:
- It is flexible
- It is well-understood
- It performs exceptionally on many tasks
However, its bottleneck means:
- Future breakthroughs may require new architectures
- Hybrid models will likely dominate
- Memory-efficient designs are critical
Transformer vs Future Architectures
Researchers are exploring:
- State-space models
- Recurrent-attention hybrids
- Neuromorphic approaches
- Event-driven sequence processing
Many of these aim to:
- Preserve Transformer strengths
- Eliminate quadratic scaling
- Enable continuous learning
The Transformer may not be the final architecture—but it set the foundation.
Read Also: AI Privacy Laws and Data Protection: Global Policy Changes You Should Know
Why Understanding This Matters
1. For developers and decision-makers:
- It explains cost behavior
- It informs system design
- It clarifies limitations
2. For researchers:
- It highlights open problems
- It guides innovation directions
3. For businesses:
- It shapes infrastructure strategy
- It influences model selection
Understanding the Transformer bottleneck is essential for realistic AI planning.
Conclusion
The Transformer architecture works by leveraging self-attention to model global relationships in data, enabling unprecedented performance across language, vision, and multimodal AI. Its ability to process sequences in parallel and learn deep contextual representations is what made modern AI possible.
However, its quadratic attention bottleneck remains the single most important limitation holding back longer contexts, lower costs, and real-time scalability.
The future of AI will likely involve:
- Transformer variants
- Hybrid architectures
- Memory-efficient attention mechanisms
But regardless of what comes next, understanding how Transformers work—and where they struggle—remains essential for anyone serious about artificial intelligence.
If you’d like, I can also provide visual diagrams, simplified explanations for beginners, or a comparison table of attention optimizations to deepen understanding further.